With the advent of Large Language Models, language processing has been revolutionized, and the potential applications are virtually limitless. However, these models have significant technical challenges in managing their deployment, training, and optimization. By implementing an effective LLMOps strategy, organizations can ensure optimal performance, scalability, and efficiency of their language models. This, in turn, enables them to leverage the full potential of these models to improve customer experience, drive revenue growth, and enhance their competitive edge. Let’s learn more about LLMOps, best practices, and techniques.
What is LLMOps?
LLMOps refers to Large Language Model Operations, which involve managing, deploying, and optimizing large language models such as Bloom, OPT, and T5. It is a set of practices and principles to bridge the gap between LLM development and deployment. It defines the automation and monitoring processes throughout the LLM development process, including integration, testing, releasing, deployment, and infrastructure management.
Generative AI solution development is a complex process involving much more than just training an LLM. In fact, as depicted in the following diagram, model training is just one of the many functions you need to take care of. Each of these elements requires technical expertise, making developing an LLM solution a highly collaborative effort involving data scientists, software engineers, DevOps engineers, and other stakeholders. The complexity of these systems increases as they are deployed in a production environment, where they must be able to handle high volumes of data, provide real-time predictions, and be highly available and reliable.
LLMOps is an emerging field that focuses on developing strategies and best practices for managing large language models, including infrastructure setup, performance tuning, data processing, and model training. An effective LLMOps strategy can ensure optimal language model performance, scalability, and efficiency, enabling organizations to unlock their full potential and gain a competitive edge.
LLMOps Architecture
Large language models require significant computational resources to process data and generate predictions, and the architecture should be designed to efficiently use hardware resources such as GPUs and TPUs. Proper LLMops design can effectively handle large volumes of data and support real-time applications by optimizing for low latency and high throughput.
A robust and automated CI/CD (Continuous Integration/Continuous Deployment) system is required to ensure that pipelines in production are updated quickly and reliably. Such a system allows data scientists to experiment rapidly with new concepts related to feature engineering, model architecture, and hyperparameters. By implementing these ideas, the scientists can automatically build, test, and deploy the new pipeline components to the target environment.
The diagram below illustrates the implementation of an LLM pipeline using CI/CD. The pipeline comprises several components: data preparation, feature engineering, model training, and deployment. The automated CI/CD system is integrated into this pipeline to facilitate each component’s automatic building, testing, and deployment.
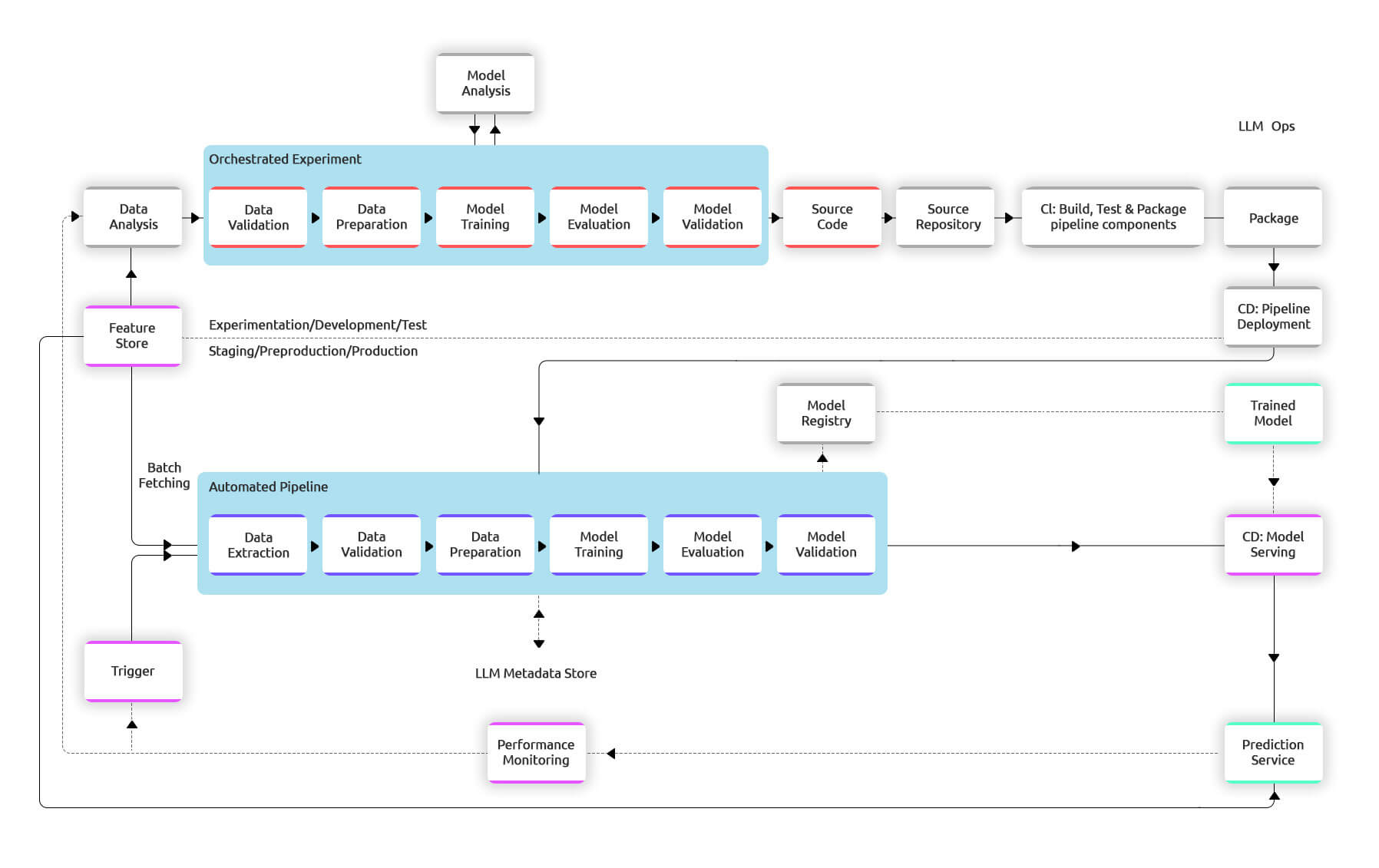
The pipeline comprises various stages to ensure a smooth training and deployment process. Initially, development and experimentation involve iterative testing of LLM algorithms and modeling, with the output being the source code for the GAI pipeline steps. Next, continuous integration involves building and testing source code, with the outputs being pipeline components for deployment. In the continuous delivery stage, artifacts from the previous stage are deployed to the target environment, resulting in a deployed pipeline with the new model implementation. The pipeline is then automatically triggered in production based on a schedule or trigger, leading to a trained model pushed to the model registry. The model is then a prediction service in the model’s continuous delivery stage. Lastly, monitoring collects statistics on model performance based on live data, providing a trigger for new pipeline execution or experiments.
Data and model analysis are still manual processes, requiring data scientists to examine data before a new experiment iteration. Continuous integration tests various aspects of the model and pipeline, including unit testing, convergence, NaN value production, artifact creation, and integration between components. Continuous delivery focuses on ensuring compatibility with target infrastructure, testing the prediction service API, load testing, validating data, verifying predictive performance targets, and deploying to test pre-production and production environments with varying levels of automation.
Recommended LLMOps tools
Various tools and frameworks are available in the market for LLMOPs, and choosing the right set of tools and frameworks can significantly improve the efficiency of the GAI solution. These tools serve different functions, such as model training, pipeline automation, continuous integration, and deployment (CI/CD). By utilizing the right set of tools and frameworks, you can enhance the performance of your language models, reduce the likelihood of errors, and achieve better results in a shorter time. Here are some tools and frameworks I recommend for different components of LLMOps.
Model Development
Developing a large language model is a complex and iterative process requiring creativity, technical expertise, and data-driven approaches. A team of experts must design and implement the model’s architecture, selecting the appropriate algorithms, optimization techniques, and hyperparameters to ensure the model can generate high-quality, coherent outputs. Once the model has been trained, it must be fine-tuned and tested to ensure it effectively generates the desired type of content.
| Tool | Function | Usage |
| Code server | Development environment | Run VS Code on any machine anywhere and access it in the browser. |
| Moby | Containerization | Moby is an open-source project created by Docker to enable and accelerate software containerization. |
| LMFlow | Finetuning | Toolbox for finetuning large machine learning models, designed to be user-friendly, speedy, and reliable |
| LORA | Finetuning | LoRA reduces the number of trainable parameters by learning pairs of rank decomposition matrices while freezing the original weights. |
| PEFT | Finetuning | Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient pre-trained language models (PLMs) adaptation to various downstream applications without fine-tuning all the model’s parameters. |
| PaddlePaddle | Training framework | PaddlePaddle (Parallel Distributed Deep Learning) is a simple, efficient, and extensible deep learning framework. |
| ColossalAI | Training framework | It supports parallel training methods such as data, pipeline, tensor, sequence parallelism, and heterogeneous training methods. |
| DeepSpeed | Training framework | DeepSpeed enables model training with a single click, offering a 15x speedup over SOTA RLHF systems with unprecedented cost reduction at all scales. |
| Aim | Experiment tracking | Aim logs all AI metadata and enables a UI to observe/compare them and an SDK to query them programmatically. |
| ClearML | Experiment tracking | ClearML is an ML/DL development and production suite containing Experiment Manager, MLOps, Data-Management, Model-Serving, and Reports. |
| Sacred | Experiment tracking | Sacred is a tool to help you configure, organize, log, and reproduce experiments. |
Model Management
Model management ensures that the model is developed efficiently and maintained effectively throughout its lifecycle. Version control allows you to keep track of changes made to the model’s code, data, and configurations, ensuring that the model can be reproduced and rolled back to previous versions if needed. Containers provide a reliable and consistent environment for running the model, enabling easy deployment and scaling. Model serving ensures that the model is accessible to users, with proper monitoring and optimization to ensure it operates correctly and efficiently. Effective model management practices enable you to confidently develop and deploy large language models.
| Tool | Function | Usage |
| Netron | Visualization | Netron is a visualization tool for neural networks, deep learning, and machine learning models. |
| Manifold | Visualization | Manifold is a model-agnostic visual debugging tool for machine learning. |
| DVC | Version Control | Data Version Control or DVC is a command line tool and VS Code Extension to help you develop reproducible machine learning projects. |
| ModelDB | Version Control | ModelDB is an open-source system to version machine learning models, including their ingredients code, data, config, and environment, and to track ML metadata across the model lifecycle. |
| Triton | Inference Serving | Triton Inference Server is an open-source inference serving software that streamlines AI inferencing. |
| TorchServe | Serving | TorchServe is a flexible and easy-to-use tool for serving and scaling PyTorch models in production. |
| FlexGen | Serving | FlexGen is a high-throughput generation engine for running large language models with limited GPU memory. |
| LangChain | Composability | LangChain enables building applications with LLMs through composability |
| LlamaIndex | Composability | LlamaIndex (GPT Index) is a project that provides a central interface to connect your LLMs with external data. |
Performance Management
Performance management is crucial in LLM solution development to ensure the model performs optimally and meets the intended objectives. Visualization tools enable developers to identify performance issues and gain insights into the model’s behavior, helping pinpoint optimization areas. Optimization techniques, such as pruning or quantization, can improve the model’s performance while reducing computational requirements. Observability tools enable developers to monitor the model’s performance and identify real-time issues, allowing for prompt remediation. By implementing effective performance management practices, developers can ensure that large language models operate efficiently, effectively, and reliably, making them suitable for various applications.
| Tool | Function | Usage |
| PocketFlow | Optimization | PocketFlow is an open-source framework for compressing and accelerating deep learning models with minimal human effort. |
| Ncnn | Optimization | ncnn is a high-performance neural network inference computing framework optimized for mobile platforms. |
| TNN | Optimization | A high-performance, lightweight neural network inference framework open-sourced by Tencent Youtu Lab |
| Whylogs | Observability | Whylogs is an open-source library for logging any kind of data. With whylogs, users are able to generate summaries of their datasets |
| Evidently | Observability | It helps evaluate, test, and monitor the performance of ML models from validation to production. It works with tabular and text data. |
| Great Expectations | Observability | Great Expectations (GX) helps data teams build a shared understanding of their data through quality testing, documentation, and profiling. |
Data Management
Data management refers to organizing, storing, tracking, and retrieving the large amounts of data used to train and fine-tune language models. This involves several key components like data storage, tracking, vector search, etc. LLMs require enormous amounts of data to be effective, often on the order of billions or even trillions of words. This data needs to be stored in a way that is efficient, scalable, and accessible to the model during training and inference. In addition to storing large amounts of data, keeping track of the metadata associated with that data is also important. Data management for large language models often involves using vector search techniques. This allows for fast and efficient searching and retrieval of similar data points, which can be useful for tasks like fine-tuning models or searching for specific examples of language use.
| Tool | Function | Usage |
| Delta Lake | Storage | Delta Lake is an open-source storage framework that enables building a Lakehouse architecture with compute engines, including Spark, PrestoDB, Flink, Trino, and Hive, and APIs for Scala, Java, Rust, Ruby, and Python. |
| DVC | Storage | Data Version Control or DVC is a command line tool and VS Code Extension to help you develop reproducible machine learning projects. |
| JuiceFS | File System | JuiceFS is a high-performance POSIX file system released under Apache License 2.0, particularly designed for the cloud-native environment. |
| LakeFS | File System | LakeFS is an open-source tool that transforms your object storage into a Git-like repository. It enables you to manage your data lake the way you manage your code. |
| PipeRider | Data tracking | PipeRider automatically compares your data to highlight the difference in impacted downstream dbt models so you can confidently merge your Pull Requests. |
| LUX | Data tracking | Lux is a Python library that facilitates fast and easy data exploration by automating visualization and data analysis. |
Deployment
Deploying LLM solutions requires careful attention to several key factors to ensure success. First and foremost, the infrastructure supporting the model must be properly sized and configured to handle the demands of the model’s computational requirements, including memory, storage, and processing power. Additionally, the model’s performance must be continuously monitored and optimized to ensure that it functions as expected, and any errors or anomalies must be addressed promptly. Another crucial consideration is data security, as large language models often deal with sensitive information that must be protected from unauthorized access or data breaches.
| Tool | Function | Usage |
| Argo Workflows | Workflow management | Argo Workflows is an open-source container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo Workflows is implemented as a Kubernetes CRD ( |
| Metaflow | Workflow management | Metaflow is a human-friendly Python/R library that helps scientists and engineers build and manage real-life data science projects. |
| Airflow | Workflow management | Tool to programmatically author, schedule, and monitor workflows. |
| Volcano | Scheduling | Volcano is a batch system built on Kubernetes. It provides a suite of mechanisms commonly required by many classes of batch & elastic workloads. |
| OpenPAI | Scheduling | Resource scheduling and cluster management for AI (Open-sourced by Microsoft). |
| Polyaxon | Orchestration | Machine Learning Management & Orchestration Platform. |
Final thoughts
LLMOPS architecture plays a vital role in the efficient and effective deployment and management of large language models. The proper LLMOPS architecture enables the infrastructure configuration to meet the model’s computational requirements, such as memory, storage, and processing power. It ensures the necessary tools and workflows are in place for data preparation, model training, and deployment, including version control and continuous integration and delivery.
Furthermore, a robust LLMOPS architecture promotes the security and privacy of data used to train the model, provides a platform for monitoring model performance, and facilitates the efficient deployment of updates or new versions of the model. Overall, a proper LLMOPS architecture is critical to realizing the full potential of large language models and achieving high performance in natural language processing applications.


