LLaMA 2 is finally here, and it doesn’t disappoint. The new model has substantial performance improvements over its predecessor and comes with the added perk of being commercially usable. As enthusiasts and developers scramble to get their hands on this powerful tool, many are eager to fine-tune LLAMA2 for various applications. In this article, we’ll learn how to fine-tune LLaMA2 using two exceptional techniques: SFT (Supervised Fine-Tuning for full parameter) and LORA (Low-rank adaptation).
A Quick Overview of LLaMA 2
Llama 2 is a collection of pretrained and fine-tuned LLMs ranging from 7 billion to 70 billion parameters. The model architecture is similar to LLaMA 1, with increased context length and the addition of Grouped Query Attention (GQA) to improve inference scalability. GQA is a standard practice for autoregressive decoding to cache the key and value pairs for the previous tokens in the sequence, speeding up attention computation. Other notable points are;
- Trained on 2 trillion tokens of data
- Increased context length of 4K
- Uses a new method for multi-turn consistency, Ghost Attention (GAtt)
LLaMA 2 Benchmark
Llama 2 models outperform Llama 1 models. In particular, Llama 2 70B improves the results on MMLU and BBH by ≈5 and ≈8 points, respectively, compared to Llama 1 65B. Llama 2 7B and 30B models outperform MPT models of the corresponding size in all categories besides code benchmarks. For the Falcon models, Llama 2 7B and 34B outperform Falcon 7B and 40B models on all categories of benchmarks. Additionally, Llama 2 70B model outperforms all open-source models.
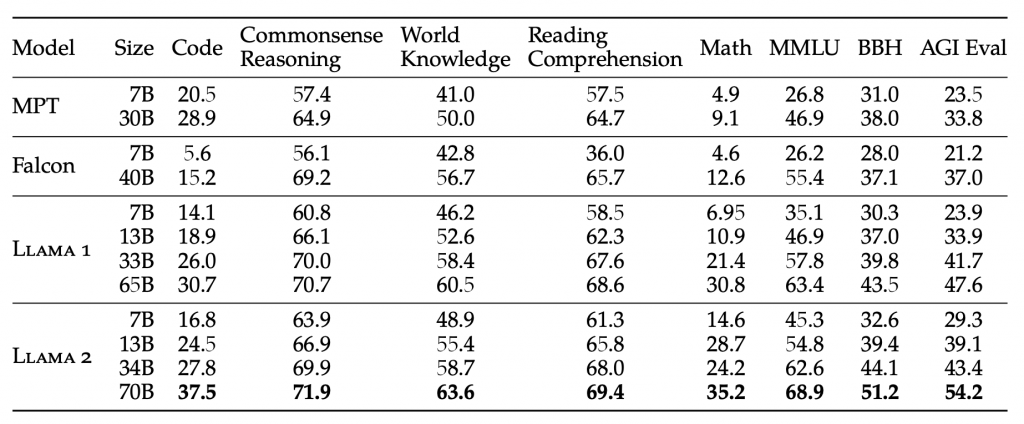
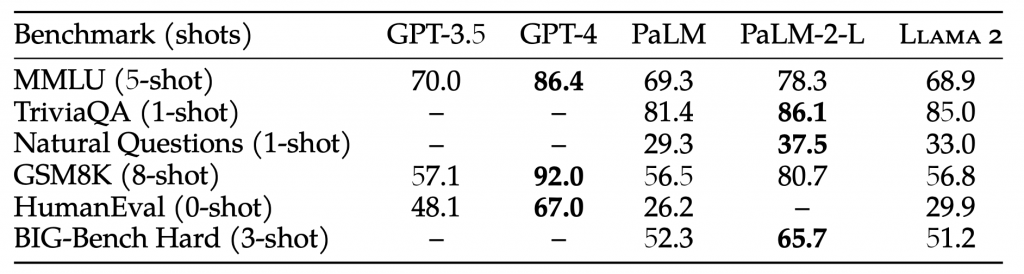
When compared with closed-source LLMs, Llama 2 70B is close to GPT-3.5 on MMLU and GSM8K, but there is a significant gap in coding benchmarks. Llama 2 70B results are on par or better than PaLM (540B) on almost all benchmarks. There is still a large gap in performance between Llama 2 70B and GPT-4 and PaLM-2-L.
How to fine-tune Llama2 using SFT
In this example, I explain the steps to fine-tune LLaMA 2 using Supervised fine-tuning (SFT). SFT fine-tunes an LLM in a supervised manner using examples of dialogue data that the model should replicate. The SFT dataset is a collection of prompts and their corresponding responses. SFT datasets can be manually curated by users or generated by other LLMs. To start the fine-tuning, the first step is to set up the development environment.
Setup Development Environment
Install torch and transformers for PyTorch and the Hugging Face Transformers library, respectively, and datasets for loading and processing datasets.
!pip install "transformers" !pip install "torch" !pip install "datasets" !pip install "peft"
Load model and tokenizer
The script loads the base model and tokenizer for the Llama model from Hugging Face Transformers using the LlamaForCausalLM and LlamaTokenizer classes.
model = LlamaForCausalLM.from_pretrained(
base_model,
# load_in_8bit=True, # Add this for using int8
torch_dtype=torch.float16,
device_map=device_map,
)
tokenizer = LlamaTokenizer.from_pretrained(base_model)
tokenizer.pad_token_id = 0
Load data
Dataset loading is based on the file format specified by the data_path argument. load a dataset either from a JSON or JSON Lines file (specified by the data_path argument as a file path) or from a dataset available in the Hugging Face datasets library (specified by the data_path argument as a dataset name). The loaded dataset is stored in the data variable, which can then be further processed and tokenized for model training.
if data_path.endswith(".json") or data_path.endswith(".jsonl"):
data = load_dataset("json", data_files=data_path)
else:
data = load_dataset(data_path)
Tokenize data
The tokenize() function is defined to preprocess the data. It encodes the input and output text data into token IDs, concatenates them, and appends an end-of-sequence token. The encoded data is then prepared as input for the model. The data is split into training and validation sets using the train_test_split() function from the datasets library.
def tokenize(data):
source_ids = tokenizer.encode(data['input'])
target_ids = tokenizer.encode(data['output'])
input_ids = source_ids + target_ids + [tokenizer.eos_token_id]
labels = [-100] * len(source_ids) + target_ids + [tokenizer.eos_token_id]
return {
"input_ids": input_ids,
"labels": labels
}
#split thte data to train/val set
train_val = data["train"].train_test_split(
test_size=val_set_size, shuffle=False, seed=42
)
train_data = (
train_val["train"].shuffle().map(tokenize)
)
val_data = (
train_val["test"].shuffle().map(tokenize)
)
input_ids are created by concatenating the token IDs of the source and target text, followed by the EOS token ID. This forms the input sequence for the language model during training. Given the input, the model will be trained to predict the target sequence.
labels are created by concatenating the list of -100 values (for the source text), followed by the token IDs of the target text, and finally, the EOS token ID. This labels list serves as the target labels for the language model during training. The model will be trained to predict the target sequence (token IDs in the labels) from the input sequence (token IDs in the input_ids).
[-100] * len(source_ids): This creates a list of -100 values with a length equal to the number of tokens in the source text. The value -100 is a special value used to mask tokens that do not require predicting (i.e., padding tokens).
Initiate the trainer
The script creates a transformers.Trainer object for training the model. It uses the train_data and val_data datasets and various training configurations such as batch size, gradient accumulation steps, number of epochs, learning rate, etc.
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=transformers.TrainingArguments(
per_device_train_batch_size=micro_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
warmup_steps=100,
num_train_epochs=num_epochs,
learning_rate=learning_rate,
fp16=True,
logging_steps=10,
optim="adamw_torch",
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=200,
save_steps=200,
output_dir=output_dir,
save_total_limit=3
),
data_collator=transformers.DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
),
)
trainer.train()
Save Model
After training, the final model is saved to the specified output_dir.
model.save_pretrained(output_dir)
Run Model
python train.py --base_model meta-llama/Llama-2-7b --data_path tatsu-lab/alpaca --output_dir output/
How to fine-tune Llama2 using LORA
Here, I explain the steps to fine-tune LLaMA 2 in this example using Low-Rank Adaptation (LoRA). LoRA proposes to freeze pre-trained model weights and inject trainable layers (rank-decomposition matrices) in each transformer block. This greatly reduces the number of trainable parameters and GPU memory requirements since gradients don’t need to be computed for most model weights.
The steps to fine-tune LLaMA 2 using LoRA is the same as of SFT. In the code, when loading the model and tokenizer, you need to specify the LoRA parameters. A sample code for fine-tuning LLaMA2 with LoRA is provided below.
from typing import List
import fire
import torch
import transformers
from datasets import load_dataset
from peft import (
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
prepare_model_for_int8_training,
set_peft_model_state_dict,
PrefixTuningConfig,
TaskType
)
from transformers import LlamaForCausalLM, LlamaTokenizer
def train(
# model/data params
base_model: str = "",
data_path: str = "",
output_dir: str = "",
micro_batch_size: int = 4,
gradient_accumulation_steps: int = 4,
num_epochs: int = 3,
learning_rate: float = 3e-4,
val_set_size: int = 2000,
# lora hyperparams
lora_r: int = 8,
lora_alpha: int = 16,
lora_dropout: float = 0.05,
lora_target_modules: List[str] = [
"q_proj",
"v_proj",
]
):
device_map = "auto"
# Step 1: Load the model and tokenizer
model = LlamaForCausalLM.from_pretrained(
base_model,
# load_in_8bit=True, # Add this for using int8
torch_dtype=torch.float16,
device_map=device_map,
)
tokenizer = LlamaTokenizer.from_pretrained(base_model)
tokenizer.pad_token_id = 0
Add this for training LoRA
config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=lora_target_modules,
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
model = prepare_model_for_int8_training(model) # Add this for using int8
# Step 2: Load the data
if data_path.endswith(".json") or data_path.endswith(".jsonl"):
data = load_dataset("json", data_files=data_path)
else:
data = load_dataset(data_path)
# Step 3: Tokenize the data
def tokenize(data):
source_ids = tokenizer.encode(data['input'])
target_ids = tokenizer.encode(data['output'])
input_ids = source_ids + target_ids + [tokenizer.eos_token_id]
labels = [-100] * len(source_ids) + target_ids + [tokenizer.eos_token_id]
return {
"input_ids": input_ids,
"labels": labels
}
#split thte data to train/val set
train_val = data["train"].train_test_split(
test_size=val_set_size, shuffle=False, seed=42
)
train_data = (
train_val["train"].shuffle().map(tokenize)
)
val_data = (
train_val["test"].shuffle().map(tokenize)
)
# Step 4: Initiate the trainer
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=transformers.TrainingArguments(
per_device_train_batch_size=micro_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
warmup_steps=100,
num_train_epochs=num_epochs,
learning_rate=learning_rate,
fp16=True,
logging_steps=10,
optim="adamw_torch",
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=200,
save_steps=200,
output_dir=output_dir,
save_total_limit=3
),
data_collator=transformers.DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
),
)
trainer.train()
# Step 5: save the model
model.save_pretrained(output_dir)
if __name__ == "__main__":
fire.Fire(train)
LoraConfig is a class provided by the PeFT framework that allows you to configure the LoRA training process. The code shows how to create a LoraConfig object with the following parameters;
r: the rank of the update matrices, expressed in int. Lower rank results in smaller update matrices with fewer trainable parameters.
lora_alpha: LoRA scaling factor
target_modules: The modules (for example, attention blocks) to apply the LoRA update matrices.
bias: Specifies if the bias parameters should be trained. Can be ‘none’, ‘all’ or ‘lora_only’.
The code further calls the get_peft_model() function to create a PeFT model by integrating the LoRA configurations into the base model. The result is assigned back to the model variable. The prepare_model_for_int8_training() function is applied to the model to enable int8 quantization. This function is part of the PeFT framework, and it prepares the model to be trained using 8-bit precision, which can help reduce the model’s memory and computational footprint. int8 quantization is an optimization technique and can be used to reduce memory usage during inference but does not affect the actual training process itself.


