Generative Pre-trained Transformer 3, more commonly known as GPT-3, is an autoregressive language model created by OpenAI. It is the largest language model ever created and has been trained on an estimated 45 terabytes of text data, running through 175 billion parameters! The models have utilized a massive amount of data from the internet, which gives them the power to generate human-like text.
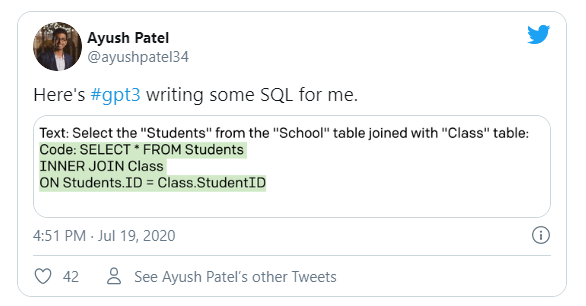
The third version of the GPT model (GPT-3) created a lot of hype in the developer community. People have posted tweets on several awesome applications built using GPT-3 API. The model is in the private beta version, but the API is available upon request. A good example of an application that was built through this model is a layout generator, where you just describe any layout you want, and it generates the JSX code for you.
This is mind blowing.
— Sharif Shameem (@sharifshameem) July 13, 2020
With GPT-3, I built a layout generator where you just describe any layout you want, and it generates the JSX code for you.
W H A T pic.twitter.com/w8JkrZO4lk
There are many other examples where developers created applications that convert natural language instruction to SQL queries, HTML, poem writing, content writing, and many more. The most amazing part is that there is no need for any fine-tuning or training of the model. Developers only have to send some sample requests to the API.
Several methods to evaluate the performance of GPT-3 were used. A few results demonstrated that, like many other AI models, GPT-3 also lacks common sense and can be fooled to generate incredibly biased text.
GPT-3 is a great milestone in the artificial intelligence community, but the hype for GPT-3 is way too high. OpenAI’s co-founder Sam Altman commented.
The GPT-3 hype is way too much. It’s impressive (thanks for the nice compliments!) but it still has serious weaknesses and sometimes makes very silly mistakes. AI is going to change the world, but GPT-3 is just a very early glimpse. We have a lot still to figure out
GPT-3 Machine Learning Model
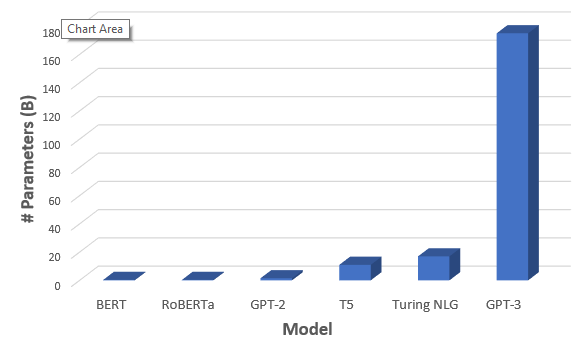
GPT-3 is trained on a massive dataset that covers almost the entire web with 500B tokens and 175 billion parameters. Compared to its previous version, it is 100x larger as well. It is a deep neural network model for language generation that is trained in such a way that it checks for the probability of a word existing in a sentence. For example, in the sentence “My father was a queen” , the word queen in this context is less probable than king in “My father was a king”. Thus by training this big neural network with almost all sorts of data from common crawl and Wikipedia, OpenAI made the GPT-3 model better than other models.
GPT-3 is actually not a novel architecture. It also uses transformers neural networks like popular language models like BERT and GPT-2. It performs much better than its predecessors, as it has been trained on a large amount of data, with extremely large model architecture and 175 billion parameters. As I said before, with this many parameters and lots of data, GPT-3 can do any NLP task like summarization, creating codes from text, writing poems, etc., without even training or fine-tuning. This is what makes GPT-3 so special. The model is not yet released, but an API is available upon request.
GPT-3, when evaluated using zero-shot and one-shot learning, shows promising performance. With few-shot training, it occasionally surpassed state-of-the-art models in the respective NLP tasks.
Getting started with GPT-3 model
Following are the steps involved in getting started with GPT-3.
- Get API token from OpenAI
- Clone the repo
- install openai
- Import modules, setup API token
- Add examples
- Submitting input
Get the API token from OpenAI
Open AI offers free access to the API through mid-August for private beta. They’re also kicking off an academic access program to let researchers build and experiment with the API. They will start with an initial set of academic researchers and collaborators who will gain free access to the API. To get the API, GO HERE and request an API, and hopefully, OpenAPI will get back to you with the access token.
How to download or install GPT-3
Clone repository — Download the gpt.py file from this repository and save it in your local machine. Thanks to Shreyashankar for her amazing repository.
Install OpenAI
pip install openai
pip install openai
Import modules and setup API token
Here, we imported the required libraries. Then we setup the api_key from the access token we get from OpenAI. Now with the gpt file we downloaded before we imported two modules GPT which is used to initialize the API with parameters and Example is used to prime the data with example types.
import json
import openai
from gpt import GPT
from gpt import Example
openai.api_key = data["API_KEY"]
with open('GPT_SECRET_KEY.json') as f:
data = json.load(f)
gpt = GPT(engine="davinci",
temperature=0.5,
max_tokens=100)
Add examples
Here we are trying to convert the natural language to SQL with the help of very few examples.
gpt.add_example(Example('Fetch unique values of DEPARTMENT from Worker table.',
'Select distinct DEPARTMENT from Worker;'))
gpt.add_example(Example('Print the first three characters of FIRST_NAME from Worker table.',
'Select substring(FIRST_NAME,1,3) from Worker;'))
Submit input and get output.
Here we sent an input as ordinary text with submit_request and got the response.
## Example - 1 prompt = "Display the lowest salary from the Worker table." output = gpt.submit_request(prompt) print(output.choices[0].text) ## Example 2 prompt = "Tell me the count of employees working in the department HR." print(gpt.get_top_reply(prompt))
Done ! Awesome right?
As I already mentioned, GPT-3 scraped almost every text data on the internet. This enabled the researchers to identify how different sentiments like sexism and racism play a role in real-world conversation. For example, the word ‘man’ can be found to have close relationships with words like strong, brave, etc., since they co-occurred more with these words when compared with the word ‘woman’.
Despite some limitations, the GPT-3 model is one of the best models for NLP tasks. Every new technology can help further mankind, and this model is just one extra step in the right direction.


