

We believe in AI and every day we innovate to make it better than yesterday. We believe in helping others to benefit from the wonders of AI and also in extending a hand to guide them to step their journey to adapt with future.
Innovations in AI technology are finding promising applications in the healthcare industry. For example, today certain AI models can detect cancer with far more accuracy than humans. Moreover, the use cases of Artificial Intelligence in the health sector earned revenues of $633.8 million in 2014 and estimates $6,662.2 million in 2021 at a compound annual growth rate of 40 percent.
With the promising benefits, medical institutions have also started improving their infrastructure by adapting to technological trends. However, like most technologies, it is safe to say that artificial intelligence also has its fair share of pitfalls. One of the most blatant of these would be its biased nature.
Healthcare institutions need to make a concentrated effort to develop AI solutions that are completely free of bias. Because a biased AI model could have a severe impact on patients’ health and well-being. But how does one go about mitigating bias in these healthcare AI applications?
The issue of bias in the medical industry is not something new. Even decades back, women and minority groups are often overlooked. We can see the occurrence of bias when there is discrimination against a particular segment of the population – either consciously through preconceived notions like racism and sexism, unconsciously through ingrained thoughts based on assumptions or stereotypes, or inadvertently through the use of data skewed towards a particular segment of the population.
A biased AI solution often leads to incorrect diagnosis and patient care recommendations. The development of any solution powered by artificial intelligence begins with data. However, healthcare data has an abundance of privacy and security issues associated with it. In fact, a recent study concluded that medical institutions that share data are much more likely to lose patients when compared to hospitals that keep patient data confidential. This makes it extremely difficult for solution developers to gather the data required to build an accurate AI model, which leads to poor quality solutions that can often make errors during diagnosis.
Winterlight Labs, a company based in Canada, implemented an AI solution in their business operations aimed to detect and identify neurological diseases. For this, the solution would first register the characteristic style in which people would speak. The data recorded will be analyzed to determine the early stage of Alzheimer’s disease. The solution claimed an accuracy of more than 90%. However, the data set that was used for training the AI algorithm solely contained samples of native English speakers. Each time a non-English speaker took the test, the solution would incorrectly perceive the pauses and mispronunciation as indicators of the disease.
Related Article Ethical AI and business challenges: How to tackle biases in Artificial Intelligence
The short answer to this question is that the output of each solution is molded by the data that has been used to train the solution. Most people are under the misconception that computer-based recommendations are completely accurate and impartial. But at the end of the day, it’s always humans who decide which data needs to be used to train a particular AI algorithm.
AI technology relies on data to train machine algorithms to make decisions. To teach a machine to estimate a factor such as a disease prevalence across various demographics. Millions of data need to be fed to make it distinguish between the target groups and contributing factors. From this, the machine learns how to make relevant distinctions. If the underlying data is inherently biased or doesn’t contain a diverse representation of target groups, the AI algorithms cannot produce accurate outputs.
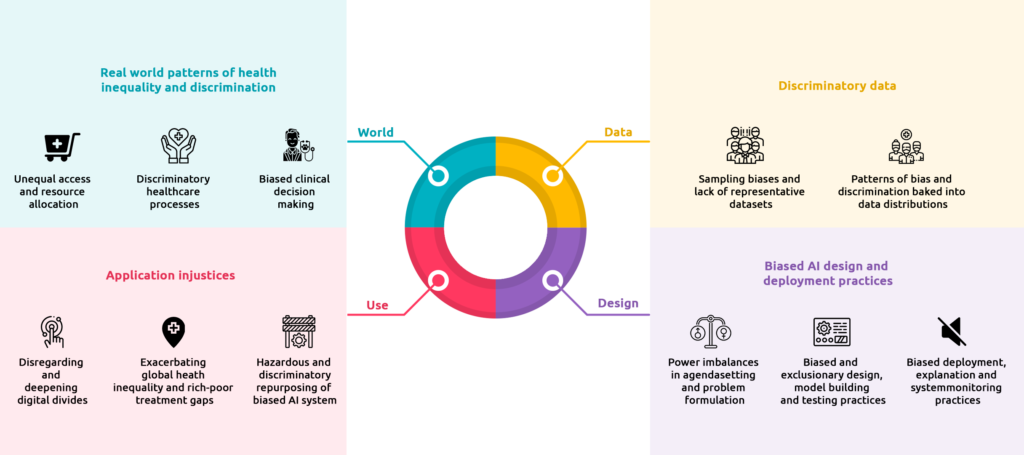
An AI solution developed by a human being will always include biases based on his understanding. Machine learning models can reflect the biases of organizational teams, designers in the team, the data scientists who implement the models, and the data engineers who gather the data. This means that such algorithms are inadvertently trained with data that is subjected to unintentional biases. So it will have an adverse effect on the underrepresented groups. Such unintentional biases can be observed at the various AI development and deployment phases. The source of these biases could either be the use of biased datasets or the application of an algorithm in a different context than it was originally intended.
For example, if the data source used to train an AI model is gathered from the academic sector of a medical center. Then the resulting AI model will learn less about the patient population that does not typically seek care at academic medical centers. Similarly, an AI model trained on a military health data source will know less about the female population, given that most service members are male. Such biased data can lead to delayed or inappropriate care delivery. That will automatically cause harm to a patient’s health. So, it is mandatory to ensure that the data used to train an AI model is representatively diverse. It helps to mitigate potential harm to the public and especially to historically marginalized populations.
One of the most commonly encountered instances while using a biased dataset would be data that doesn’t adequately represent the target population. These datasets can have a far-reaching negative impact on certain groups in a population. For instance, classification based on gender and color is generally underrepresented in clinical trials. Consider an AI solution that is developed for skin analysis. If this solution is trained with images that are predominantly of white patients, then the model will give accurate results for white people. But the diagnosis of others will be incorrect. This means that such a solution could miss malignant melanomas in people of color, leading to incorrect diagnoses and potential fatalities.
Now, what if the data being used to train the solution is completely free of bias?
You might assume that this would completely get rid of biases in an AI solution. However, the solution is not as simple as that. Many choices that are made during data processing and algorithm development can also contribute to bias. For instance, minor differences between population groups might be overlooked to build a one-size-fits-all model. Additionally, many diseases appear differently in women and men. This includes cardiovascular disease, diabetes, and even mental health disorders such as depression and autism. An AI solution needs to consider these differences, else this might exacerbate existing gender inequalities.
Reach out to us for a free AI consultation
To mitigate bias and prevent AI from worsening existing inequalities, it is essential to understand the bias that seeps into an algorithm. So, we need to ideate strategies on how to prevent it through careful design and implementation.
A few key points that can be kept in mind while trying to mitigate bias include:
The first step in mitigating bias is to anticipate the possibility of its occurrence in an algorithm. Audit the developed algorithm and look for potential sources of bias that could result in unequal outcomes when tested on a target population.
The data that you collect will not always be entirely accurate. Thoroughly analyze each data and look for imperfections or mistakes that could lead to incorrect output. If you are building an AI algorithm to detect signs of mental disorder then, you need to include extensive information on people suffering from depression. However, the data on people diagnosed with schizophrenia might be significantly lesser in volume. This could be considered a major flaw in your data set.
Several factors need to be taken into account while looking for data sets to train your algorithm with. Make sure that you consider these factors to ensure fairness across different segments of the population. An effective way to do this would involve adjusting thresholds within the model to ensure equal outcomes and allocation of healthcare resources.
To develop an effective AI model, you will need to remember that your work doesn’t just end after deployment. Keep monitoring the data for any discrepancies that you may have missed during the development process. Testing a model in a controlled setting is very different from deploying it in a real-life scenario. So, that needs to be taken into account to prevent bias.
To get the right feedback for your model, you need to understand the mistakes in the output that is being displayed. And should try to rectify it.
One of the main reasons for the inclusion of bias during the development of a model is a homogenous workforce. When you are hiring your development team, try to diversify your workforce and include people from various segments of the population. By promoting an inclusive culture, you are reducing the chances of bias during development. To ensure that the minority groups are adequately represented.
Promote collaboration between your solution development team and healthcare experts. This can help you integrate a contextual understanding of medical care into your AI solutions. For instance, as mentioned earlier, many diseases manifest themselves differently in various ethnic groups and genders. By integrating the knowledge of medical experts, it will be much easier to anticipate such cases and act accordingly.
If your data sets aren’t of the best quality, it can severely impact the output of your AI algorithm. This is why you need to include well-annotated and curated datasets that are inclusive of all population segments.
The developed AI algorithm needs thorough validation to make sure that it executes tasks as required. This means it needs to be assessed using not only traditional accuracy metrics but also relevant fairness metrics. There is a large chance that your algorithm needs to be retrained and recalibrated when applied to patients across different countries or ethnicities.
As AI solutions are becoming increasingly prevalent in healthcare, organizations must address the issue of algorithmic bias. If the intention is to develop a more equitable healthcare solution, we need better mechanisms to balance the risks and benefits of AI technology. Collaboration between data scientists, healthcare providers, consumers, and regulators is needed to achieve this goal. To develop an ethical AI ecosystem that will improve medical care, medical institutions and organizations must begin analyzing AI for bias and fairness. This can help mitigate bias and provide top-notch medical care to patients all around the world.
Reach out to us for a free AI consultation




