Hi Readers! I’ve decided to start a blog series, in which I’d summarize a technical paper each week. The paper we will be discussing in this blog is on how to scale Hyperledger fabric to 20,000 Transactions per second.
Hyperledger fabric is the most popular, production ready permissioned blockchain developed by IBM, now maintained under the Linux Foundation. Higher throughput was always a challenge for blockchain technologies, the paper tries to address this issue and put forward a couple of plug and play optimizations in the Fabric architecture to enhance its performance from 3K to 20K transaction per second.
The blog is meant for esoteric readers with sound knowledge in the working of blockchain and hyperledger fabric. We will not explicate or revisit any of the basics in the blog; this would be pure research paper analysis.
Architectural Optimisation
The paper revisits the conventional system design optimizations in the first section to enhance the performance by a factor of 7. The block latency plays a significant role in less throughput, the section describes 4 methods to optimize this in the architecture level
- Separating metadata from data – The consensus part of fabric receives whole transaction as input, this includes all the details regarding the transactions but this layer only relies on the transaction ID to order the transactions, so the suggestion is to re-architect to send only the transaction ID to this layer
- Parallelism and caching – Another paper published by the IBM research team also emphasizes on aggressive caching, we cannot optimize an architecture without introducing parallelism in the executions. There are some aspects in the fabric transaction flow that can be parallelized.The idea is to cache as many un-marshalled blocks as possible in the committers and paralleliszing all the possible validations, including endorsement policy validation and syntactic verification.
- Exploiting the memory hierarchy for fast data access on the critical path – The Fabric uses a key-value pair database to save the world state, I have discussed how we changed from a key-value in memory database to a data structure to optimize our trade engines performance.This paper also suggest moving the world state from in-memory database to a data structure, the authors suggest hash table for faster access to the data on critical transaction-validation path, deferring the storage to a write-optimized storage cluster.
- Resource separation – The paper put forward an approach where we provide separate hardware for endorser and commiter role of peer.
[contact_sales title=”Need help with Blockchain development?” desc=”Let’s work together!” btn_text=”View Our Services” url=”https://accubits.com/services/blockchain/”]
Paper Structure
The paper broadly classified into 4 main sections, the first section is the introduction and brief idea about the paper which we have discussed in the preceding section.
- Section II – Gives a brief overview of working of hyperledger fabric, we would not go into this section in a succinct manner but will only provide a comprehensive note. Please refer to the paper or hyperledger documentation if you want to explore more, links in the reference section.
- Section III – Gives a detailed description of the proposed optimizations, we would be including our thoughts and experience working and implementation of such solutions.
- Section IV – Discuss the experimental details regarding the proposed solutions.
Fabric Architecture
The structure of hyperledger fabric is really interesting; it stands out from the rest of blockchain and follows an execute-order-commit instead of the common order-execute-commit pattern. The transaction is first send to a sand box which executes it and read-write sets are determined, this is then ordered using an ordering service, and finally validated and committed to the blockchain. Clients originate transactions, i.e., reads and writes to the blockchain, that are sent to Fabric nodes. Nodes are either peers or orderers; some peers are also endorsers. All peers commit blocks to a local copy of the blockchain and apply the corresponding changes to a state database that maintains a snapshot of the current world state. Endorser peers are permitted to certify that a transaction is valid according to business rules captured in chaincode, Fabric’s version of smart contracts. Orderers are responsible solely for deciding transaction order, not correctness or validity.
Transaction Flow
A client sends its transaction to some number of endorsers. Each endorser executes the transaction in a sandbox and computes the corresponding read-write set along with the version number of each key that was accessed. Each endorser also uses business rules to validate the correctness of the transaction. The client waits for a sufficient number of endorsements and then sends these responses to the orderers, which implement the ordering service. The orderers first come to a consensus about the order of incoming transactions and then segment the message queue into blocks. Blocks are delivered to peers, who then validate and commit them.
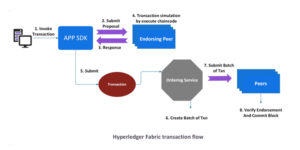
Design
The paper put forward solutions to upgrade in the ordering services and peer tasks to bring hyperledger fabric performance.
Orderer Improvement I
There is a wide belief that hyperledger uses the BFT consensus for the 1.2 version but actually it just uses Apache Kafka to order the transaction, The latest version came with support to Raft consensus.The proposed solution as mentioned in the earlier section is to reduce the communication overhead by separating transaction ID from the whole transaction payload. The kafka ordering service only requires transaction id, so the ordering service should extract the transaction id and send it to the kafka cluster the rest of the payload is retained in a data structure. The transaction is reassembled when the ID is received back from Kafka. Subsequently, as in Fabric, the orderer segments sets of transactions into blocks and delivers them to peers. This approach works even when there would be a considerable change in the consensus hyperledger
Orderer Improvement II
The execution of transactions is consecutive; this shuts down the whole possibility of parallel processing. The ordering service handles one transaction at a time from the client. When a transaction is arrived
- The corresponding channel is identified.
- The validity is verified against specific rules.
- Then passed on to the consensus system and the next transaction is fetched.
The paper proposes a solution of message pipe lining to fetch and process multiple requests at once. The multiple transactions are sent to the message pipeline and executed parallely once we get the output of the transaction they are forwarded back to the client. It is also suggested to use a thread per incoming transaction and maintain a pool of thread connections using GRPC, all this increases the performance of parallel executions.
Peer Task Improvement I
The paper cites the observations that they have made in the the validation of a transaction’s read and write set needs fast access to the world state. Thus, we can speed up the process by using an in-memory hash table instead of a database. The world state database must be looked up and updated sequentially for each transaction to guarantee consistency across all peers.This in turn reduces the costly database read and write thus reducing the access time significantly. This introduces a new problem of volatility that is addressed in the following section.
Peer Task Improvement II
The fabric uses a level db or couch db to store the world state and block data. Decoupling this storage from other peer tasks is a proposed solution from this paper. For maximum scaling, we propose the use of a distributed storage cluster. Note that with this solution, each storage server contains only a fraction of the chain, motivating the use of distributed data processing tools such as Hadoop MapReduce or Sparkr.
Peer Task Improvement III
The fabric version 1.2 – 1.4 uses the endorser to commit the blocks, the first instinct would be to cluster the endorser. This is a great approach but the problem is the transaction processing and committing occurs congruously. This nullifies the clustering approach we discussed, so we should split these to operations.The design discusses a solution wherein we split transaction validation and commiter into two different hardware as well as process, the committer peer executes the validation pipeline and send the result to the endorser which will just update the world state.
This approach also helps in scaling out to meet the demand by increasing the cluster, the paper emphasis on the point of usage of separate hardware for this.
Peer Task Improvement IV
Both block and transaction header validation, which include checking permissions of the sender, enforcing endorsement policies and syntactic verification, are highly parallelizable. The paper suggests allocating one Go routine per transaction validation, this way we will be able to process multiple validation at the same time. Finally, all read-write sets are validated sequentially by a single goroutine in the correct order. This enables us to utilize the full potential of multi-core server CPU’s
Peer Task Improvement V
The hyperledger fabric uses Grpc protocol(the rpc protocol developed by google), Protobuf are used to serialize the data. This is considered the fastest/popular method for faster communication within services. The hyperledger however has an overhead here, since there are constant updates in the application level the team has layered these data at different points, hence unnecessary marshalling and unmarshalling of data transpire at all these layers of the block. The paper suggests implementing a layer of caching for this marshaling and unmarshalling of data, this fetches the cache value until a new block arrives.
Blocks are stored in the cache while in the validation pipeline and retrieved by block number whenever needed.Once any part of the block becomes unmarshalled, it is stored with the block for reuse. We implement this as a cyclic buffer that is as large as the validation pipeline.Since we are just saving and reading the data this can be a lock free operation and we are sure that only one block is committed after another we can make this process parallel as well as lock-free.
Final Thoughts
The paper suggests some insightful optimization based on the conventional system design and parallelism, some of the optimization mentioned are really good but some of them introduces new overhead like maintenance, for eg: the maintenance of data structure instead of an in-memory would definitely bring up the issue of volatility thus we need to take into account the disaster recovery in this case. The hyperledger fabric comes in a beautiful packaging of docker, they have built and containerized all these applications in dockers and supporting scripts to bring up this complex architecture. The fabric has lots of moving pieces in its architecture, to implement these changes and carry out experiments the team behind the paper have removed the docker components and ran the services in a bare Linux machine.We personally do not suggest running these services without docker as it would be really hard to maintain this network in such a scenario. The introduction of message pipe-lining fixes another problem that is not being mentioned in the paper sometimes the peer restarts the connection thus bringing issues to the stability of the network, this problem was also observed in the event hub section which was removed in the fabric 1.4, if all the communication are through message pipeline then this decrease the chance of such issues from happening. This comes with the disadvantage of increased infrastructure, but we believe that this is a trade off that the developer should make while implementing an application.
Some related works point out multiple use of certificates and hashes also brings a bottleneck to the system, aggressive caching can increase the speed but comes with a little trade-off to the security part of it.
[contact_sales title=”Need help with Blockchain development?” desc=”Let’s work together!” btn_text=”View Our Services” url=”https://accubits.com/services/blockchain/”]
References
- Performance Benchmarking and Optimizing Hyperledger Fabric Blockchain Platform : https://arxiv.org/pdf/1805.11390.pdf
- FastFabric: Scaling Hyperledger Fabric to 20,000 Transactions per Second: https://arxiv.org/pdf/1901.00910.pdf


