We believe in AI and every day we innovate to make it better than yesterday.
We believe in helping others to benefit from the wonders of AI and also in
extending a hand to guide them to step their journey to adapt with future.
In this article, we’ll learn how to do vector similarity search using elasticsearch. Before jumping into the tutorial, let’s brush up on our knowledge and familiarise the basics of elasticsearch semantic search, vector similarity, similarity search, etc. You’re welcome to skip the intro and jump to topics that interest you from the index below.
Elasticsearch is an open-source, distributed search engine for search and analytics built on Apache Lucene. It enables users to store, search, and analyze large volumes of data quickly and in near real-time. Elasticsearch is an underlying technology that powers applications with complex search features and requirements.
Elasticsearch, along with its ecosystem of components known as Elastic Stack, has found applications in various areas, including simple searches on websites or documents, collecting and analyzing log data, data analysis, and visualization.
Semantic search
An easy way to perform a similarity search would be to rank documents based on how many words they share with the query. But a document may be similar to the query even if they have very few words in common. This is why semantic search is important.
The semantic search involves a type of search often seen in search engines. It retrieves content after comprehending the intent and meaning of the user’s search query. Semantic search is much more advanced than traditional text and keyword match searches. Traditional keyword search does not consider lexical variants or conceptual matches to the user’s search phrase. If the precise wording used in the query cannot be found in the overall content, incorrect results will be provided to the user. This type of search is based on two concepts:
Search intent of the user: This refers to the intention behind the user’s search. It involves decoding the reason behind the question. This reasoning could be anything from wanting more knowledge to finding a particular purchase item. By understanding the intent behind the query, search engines can retrieve the most accurate results for the users.
Relationship between the words in the search phrase: It is essential to decoding the meaning of all the words together in the search phrase instead of the individual words. This means understanding the relationship between those words, thus displaying results conceptually similar to the user’s query.
Use-cases of Semantic Similarity Search:
Question-answering system: Given a collection of frequently asked questions, the search can find questions with the same meaning as the user’s new query. It can then provide stored results of similar questions.
Image search – In a dataset of captioned images, it can find images whose caption is similar to the user’s description.
Document content search – Allows searching through several documents to find one that matches the user’s requirements.
Article search – In a collection of articles, it can return articles with a title closely related to the user’s query.
What is vector similarity?
Vector similarity measures the similarity between two vectors of an inner product space. It is measured by the cosine of the angle between two vectors and determines whether two vectors are pointing in roughly the same direction. It is often used to measure document similarity in text analysis.
A document can be represented by thousands of attributes, each recording the frequency of a particular word (such as a keyword) or phrase in the document. Thus, each document is an object represented by a term-frequency vector. Each vector element is associated with a word in the document, and the value is the number of times that word is found in the document in question. The vector similarity is then computed between the two documents.
Conducting semantic search
Semantic search can be implemented through a variety of different approaches. NLP specialists have developed a unique technique known as text embeddings. Text embedding involves converting words and sentences into fixed-size dense numeric vectors. This means that any kind of unstructured text can be converted to vectors. These vectors enable the understanding of the contextual meaning of the text and can be used to find the similarity between the user query and the web pages. If the text embeddings to two texts are similar, the two texts are semantically similar. These vectors can be indexed in Elasticsearch to perform semantic similarity searches.
Using embeddings for similarity search
Text embeddings can be used to retrieve questions that are similar to a user’s query. This is done through the following process-
Each question is run through a sentence embedding model during indexing to produce a numeric vector.
A query is run through the same sentence embedding model to produce a vector when a user enters a query. We calculate the similarity between each question and the query vector to rank the responses. When comparing embedding vectors, it is common to use cosine similarity.
Recalling Cosine Similarity
Cosine similarity is a metric used to measure the similarity of documents, irrespective of their size. Mathematically, it measures the cosine of the angle between two vectors projected in a multi-dimensional space. The cosine similarity is advantageous because even if the two similar documents are far apart by the Euclidean distance (due to the size of the document), chances are they may still be oriented closer together. The smaller the angle, the higher the cosine similarity.
Tutorial: Implementing a QA system
Let’s implement a simple question-answering search engine using elasticsearch and a sentence embedding architecture.
Setting up Elasticsearch
Download and extract the archive
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.1-linux-x86_64.tar.gz
tar -xzf elasticsearch-7.9.1-linux-x86_64.tar.gz
Launch elasticsearch server
cd elasticsearch-7.9.1
./bin/elasticsearch
All done! Now let’s see if the elasticsearch node is up and running by sending an HTTP request to port 9200 (default port of es node).
Run the following command from your terminal
curl -X GET "localhost:9200/?pretty"
The above command returns something similar to this:
Note: If you are using a non Linux distribution, download your OS compatible package from Elasticsearch Download Page
Choosing an embedding model
We must generate embeddings for our textual information to perform a semantic search. Since we are dealing with questions, we will use a sentence embedding model to generate the embeddings. Sentence embedding techniques represent whole sentences and their semantic information as vectors. This helps understand the text’s context, intent, and other nuances. Some of the state-of-the-art sentence embedding techniques are:
Doc2Vec
SentenceBERT
InferSent
Universal Sentence Encoder
We will be using Universal Sentence Encoder for generating sentence embeddings. The universal encoder supports several downstream tasks and thus can be adopted for multi-task learning, i.e., the generated sentence embeddings can be used for multiple tasks like sentiment analysis, text classification, sentence similarity, etc.
Julia Vs Python
Benchmarking and performance analysis of Julia Vs Python
Universal Sentence Encoder is based on two encoders, Transformer and Deep Averaging Network(DAN). Multi-task learning is possible because both models are general-purpose.
The input sentence is tokenized according to the PTB method (Penn Treebank) and passed through one of these models.
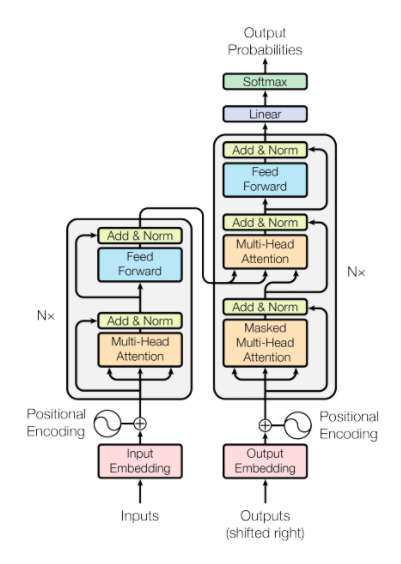
Transformer
Transformer architecture was developed by Google in 2017. It leverages self-attention with multi blocks to learn the context-aware word representation.
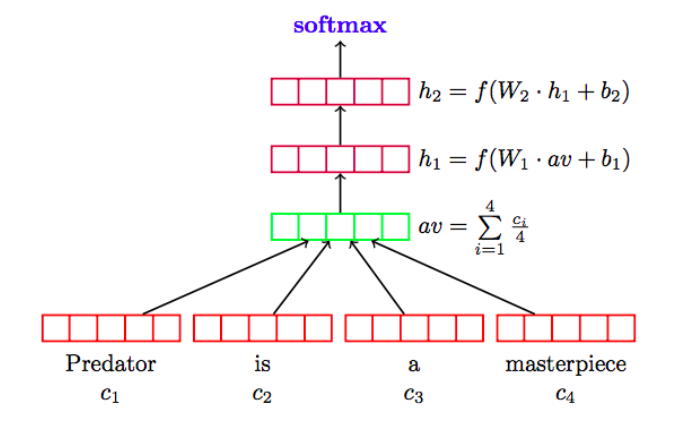
Deep Averaging Network (DAN)
The Deep Averaging Network (DAN) is a very simple model in which the word embeddings of the input text are simply averaged and then fed to a feed-forward neural network.
The transformer architecture performs better but requires more resources to train. Although DAN doesn’t work as well as the transformer architecture. The advantage of DAN is a simple model that requires fewer training resources.
Setting up the environment
Step 1 – Clone the project repo
git clone https://github.com/adarsh-ops/semantic-qa.git
cd semantic-qa
Step 2 – Install dependencies
pip install requirements.txt
Indexing the dataset
The dataset used in this project is from COVID-Q, a dataset of 1,690 questions about COVID-19 from thirteen online sources. The dataset is annotated by classifying questions into 15 question categories and by grouping questions that ask the same thing into 207 question classes.
First, index our dataset in the elasticsearch node to create a search space.
question – text field to hold questions in the dataset
answer – text field to answer the respective question
question_vec – 512-dimensional vector representation (embedding) of the question
q_id – Id of type long to represent the question id
Step 2 – Define the required configs in config.py
# Universal Sentence Encoder Tf Hub url
MODEL_URL = "https://tfhub.dev/google/universal-sentence-encoder/4"
# Elasticsearch ip and port
ELASTIC_IP = "localhost"
ELASTIC_PORT = 9200
# Min score for the match
SEARCH_THRESH = 1.2
Step 3 – Index the question vectors and answers
Run the dump_qa.py file to index the dataset at data/COVID-QA.csv
python dump_qa.py
This creates an index named “covid-qa” in the elasticsearch node with the mapping defined in step 1.
Index each QA pair in the dataset along with the Question ID and generate embedding into covid-qa index
for _, row in tqdm(df.iterrows()):
insert_qa({
'question': row['Question'],
'answer': row['Answers'],
'question_vec': np.asarray(model([row['Question']])[0]).tolist(),
'q_id': row['Question ID']
})
Here, the model([row[‘Question’]])generates a 512-dimensional embedding for the given question.
Building a search API
With the search space created, all that is left to do is define the semantic search criteria. For this, let’s build an API for returning ‘top_n’ results given a search query (question).
Step 1 – Define the API server and load configs
from flask import Flask, request
app = Flask(__name__)
app.config.from_object('config')
Step 2 – Load the universal-sentence-encoder and connect it to es node
model = hub.load(app.config['MODEL_URL'])
connect_elastic(app.config['ELASTIC_IP'], app.config['ELASTIC_PORT'])
For estimating the nearest ‘n’ records, cosine similarity between the query vector and the indexed question vectors are calculated. Ideally, the cosine similarity range is [-1, 1]. To change the score into real positive values, adding ‘1’ to the score will update the range to [0, 2].
result = es_conn.search(index="covid-qa", body=s_body)
for hit in result["hits"]["hits"]:
print("--\nscore: {} \n question: {} \n answer: {}\n--".format(hit["_score"], hit["_source"]['question'], hit["_source"]['answer']))
Step 4 – Define the API to perform a semantic search
@app.route("/query", methods=["GET"])
def qa():
if request.args.get("query"):
query_vec = np.asarray(model([request.args.get("query")])[0]).tolist()
records = semantic_search(query_vec, app.config['SEARCH_THRESH'])
else:
return {"error": "Couldn't process your request"}, 422
return {"data": records}
For performing the semantic vector match, we need to represent the raw text query as embeddings, model([request.args.get(“query”)]) generates a 512-dimensional embedding for the input query.
Step 5 – Run the API server
app.run(host="0.0.0.0", port=5000)
The server will be up and running on port 5000 of your machine.
So far, we’ve discussed semantic similarity, its applications, implementation techniques and built a simple QA engine using elasticsearch and a universal sentence encoder.
Semantic matching is helpful in applications like paraphrase identification, question answering, natural language generation, and intelligent tutoring systems. In short, if we want our system to be robust regarding grammatical reasoning, we would need to add a semantic analyzing technique. In some use cases, a hybrid approach may perform better. The QA engine we built earlier can be made more efficient by introducing text pre-processing techniques like cleansing, stopping word removal, etc.
Frequently Asked Questions
We have compiled some commonly asked questions for your convenience. If you don’t see the answer you’re looking for, please send us your question, and our team of experts will respond with accurate information within 24 hours.
What is vector similarity search?
Vector similarity search is a method of retrieving data or information from a large dataset by comparing the similarities between vectors. In other words, it is a search technique that helps to find similar items based on their vector representations. This method is widely used in various fields, including natural language processing, image recognition, and recommendation systems. Its effectiveness lies in quickly and accurately identifying items similar to a given query item, making it an important tool for data analysis and retrieval.
Which model is best for semantic similarity?
Several models are commonly used for semantic similarity, and the best model largely depends on the specific task and data being analyzed. Some popular models include word embeddings, Word2Vec, and GloVe, and more complex models, like BERT and Transformer-based models. These models are designed to capture the underlying semantic relationships between words and phrases and can be trained on large datasets to improve their accuracy. Ultimately, the choice of which model to use will depend on factors such as the size and complexity of the data, the task at hand, and the specific goals of the analysis.
What are the benefits of vector search?
Some of the prominent benefits of vector search include:
Enables fast and accurate retrieval of information or data from large datasets
Efficient searching and clustering of similar items based on their vector representations
Improves the speed and accuracy of data analysis
It helps to uncover hidden relationships and patterns within the data
It can be used in various fields, including natural language processing, image recognition, and recommendation systems
Enables the identification of similar items based on their vector representations
It can be trained on larger datasets to improve its overall accuracy
Provides a powerful tool for data retrieval and analysis, leading to new insights and discoveries
How do you find semantic similarity?
Semantic similarity can be found using various techniques, depending on the specific task and data being analyzed. Here are some common methods:
Word embeddings: This involves representing words or phrases as high-dimensional vectors and measuring the cosine similarity between the vectors. The higher the cosine similarity between two vectors, the more semantically similar the words or phrases are.
Latent Semantic Analysis (LSA): This involves performing a singular value decomposition on a term-document matrix to identify the underlying latent semantic relationships between words.
Latent Dirichlet Allocation (LDA): This topic modeling algorithm identifies the latent topics within a corpus of text and assigns each document a probability distribution over these topics. Semantic similarity can then be found by comparing the probability distributions of two documents.
BERT and other transformer-based models: These deep learning models use attention mechanisms to understand the context and meaning of words and phrases within a sentence. Semantic similarity can be found by measuring the similarity of the output representations of two sentences.
Overall, the method used to find semantic similarity will depend on the specific task and data being analyzed, as well as the desired level of accuracy and complexity of the analysis.
What is Elasticsearch used for?
Elasticsearch is a search engine widely used for indexing, searching, and analyzing large volumes of data. It is a powerful and flexible tool that can be used for a wide range of applications, including:
Enterprise search: Elasticsearch can search and analyze large volumes of data across an organization, including data from multiple sources and formats.
eCommerce search: Elasticsearch can power product search and recommendations on e-commerce websites, improving the accuracy and relevance of search results.
Log analysis: Elasticsearch can be used to index and analyze log data from various sources, including applications, servers, and network devices, enabling users to troubleshoot issues and identify trends.
Security analytics: Elasticsearch can be used to detect security threats and anomalies in real time by analyzing large volumes of security-related data, including network traffic, logs, and user activity.
Business analytics: Elasticsearch can be used to analyze business data, including customer behavior, sales trends, and marketing campaigns, enabling users to make data-driven decisions.
What are the benefits of Elasticsearch?
Fast and accurate search: Elasticsearch provides fast and accurate search capabilities, allowing users to search and retrieve data in real-time.
Scalability: Elasticsearch is designed to be highly scalable, allowing users to easily add or remove nodes as needed to handle large volumes of data.
Distributed architecture: Elasticsearch uses a distributed architecture, enabling users to distribute data across multiple nodes and perform parallel processing for improved performance.
Flexible data modeling: Elasticsearch provides a flexible approach, allowing users to index and search data in various formats and structures.
Full-text search: Elasticsearch provides full-text search capabilities, allowing users to search for keywords and phrases across large volumes of data.
Real-time analytics: Elasticsearch provides real-time analytics capabilities, allowing users to analyze and visualize data.
Machine learning integration: Elasticsearch integrates with machine learning tools, enabling users to perform advanced analytics and predictive modeling.
Open source: Elasticsearch is open-source software, meaning that it is freely available and can be customized and extended by developers to meet specific needs.