I hope we all agree that our future will be highly data-driven. In today’s connected and digitally transformed the world, data collected from several sources can help an organization to foresee its future and make informed decisions to perform better. Businesses, enterprises, government agencies, and other organizations which realized this, is already on its pursuit to tap the different data flows and extract value from it through big data ingestion tools.
The future is data-driven!
So far, businesses and other organizations have been using traditional methods such as simple statistics, trial & error, improvisations, etc to manage several aspects of their operations. For example, introducing a new product offer, hiring a new employee, resource management, etc involves a series of brute force and trial & errors before the company decides on what is the best for them. This is evidently time-consuming as well as it doesn’t assure any guaranteed results. However, the advancements in machine learning, big data analytics are changing the game here. New tools and technologies can enable businesses to make informed decisions by leveraging the intelligent insights generated from the data available to them.
All hail data!
Businesses need data to understand their customers’ needs, behaviors, market trends, sales projections, etc and formulate plans and strategies based on it. In this age of Big Data, companies and organizations are engulfed in a flood of data. The data has been flooding at an unprecedented rate in recent years. All of that data indeed represents a great opportunity, but it also presents a challenge – How to store and process this big data for running analytics and other operations.
With the incoming torrent of data continues unabated, companies must be able to ingest everything quickly, secure it, catalog it, and store it so that it is available for study by an analytics engine. When various big data sources exist in diverse formats, it is very difficult to ingest data at a reasonable speed and process it efficiently to maintain a competitive advantage. It’s hard to collect and process big data without appropriate tools and this is where various data Ingestion tools come into the picture.
[contact_sales title=”Big Data for Accelerated Business Growth” desc=”Reach out to us today to learn more.” btn_text=”Get Consultation” url=”https://accubits.com/contact/”]
The challenge
Harnessing the data is not an easy task, especially for big data. A typical business or an organization will have several data sources such as sales records, purchase orders, customer data, etc. The picture below depicts a rough idea of how scattered is the data for a business. The challenge is to consolidate all these data together, bring it under one umbrella so that analytics engines can access it, analyze it and deduct actionable insights from it.
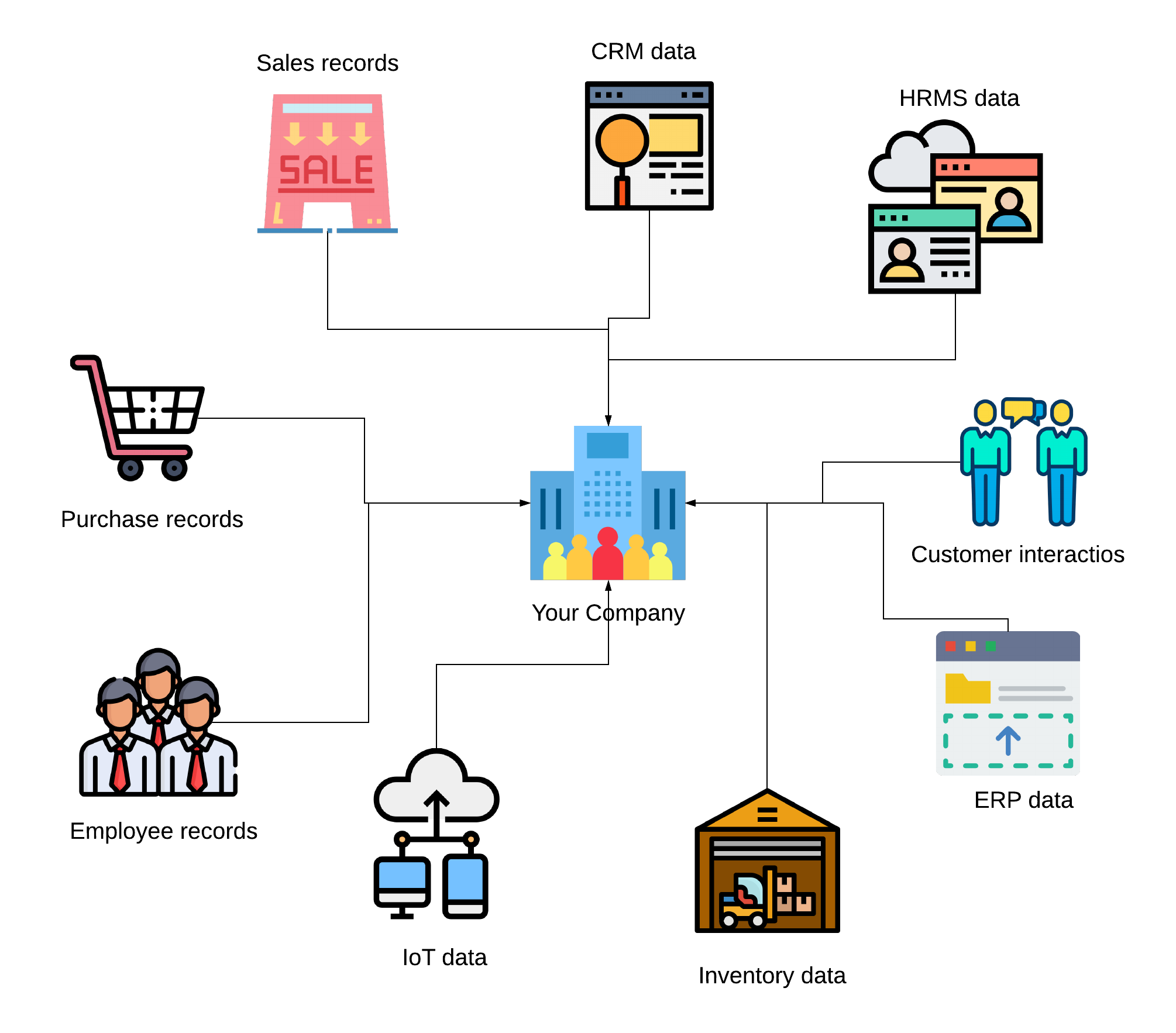
Big data ingestion: How to do it right
Data Ingestion tools are required in the process of importing, transferring, loading and processing data for immediate use or storage in a database. The process involves taking data from various sources, extracting that data, and detecting any changes in the acquired data. With data ingestion tools, companies can ingest data in batches or stream it in real-time. Ingesting data in batches means importing discrete chunks of data at intervals, on the other hand, real-time data ingestion means importing the data as it is produced by the source. An effective data ingestion tool ingests data by prioritizing data sources, validating individual files and routing data items to the correct destination. Data must be stored in such a way that, users should have the ability to access that data at various qualities of refinement.
Choosing the Right Data Ingestion Tool
Choosing the right tool is not an easy task. To achieve efficiency and make the most out of big data, companies need the right set of data ingestion tools. There are some aspects to check before choosing the data ingestion tool. Before choosing a data ingestion tool it’s important to see if it integrates well into your company’s existing system. Data ingestion tools should be easy to manage and customizable to needs. A person with not much hands-on coding experience should be able to manage the tool. Apart from that the data pipeline should be fast and should have an effective data cleansing system. Start-ups and smaller companies can look into open-source tools since it allows a high degree of customization and allows custom plugins as per the needs.
An ideal data ingestion tool should have the following features
Data flow Visualization: It allows users to visualize data flow. A simple drag-and-drop interface makes it possible to visualize complex data. It helps to find an effective way to simplify the data.
Scalability: A good data ingestion tool should be able to scale to accommodate different data sizes and meet the processing needs of the organization.
Multi-platform Support and Integration: Another important feature to look for while choosing a data ingestion tool is its ability to extract all types of data from multiple data sources – Be it in the cloud or on-premises.
Advanced Security Features: Data needs to be protected and the best data ingestion tools utilize various data encryption mechanisms and security protocols such as SSL, HTTPS, and SSH to secure data. It should comply with all the data security standards.
There are so many different types of Data Ingestion Tools that are available for different requirements and needs. Here are some of the popular Data Ingestion Tools used worldwide.
Apache NIFI
Apache NIFI is a data ingestion tool written in Java. The tool supports scalable directed graphs of data routing, transformation, and system mediation logic. It offers low latency vs high throughput, good loss tolerant vs guaranteed delivery and dynamic prioritization. NIFI also comes with some high-level capabilities such as Data Provenance, Seamless experience between design, Web-based user interface, SSL, SSH, HTTPS, encrypted content, pluggable role-based authentication/authorization, feedback, and monitoring, etc. It is also highly configurable.
Gobblin
Gobblin is another data ingestion tool by LinkedIn. It is open source and has a flexible framework that ingests data into Hadoop from different sources such as databases, rest APIs, FTP/SFTP servers, filers, etc. The advantage of Gobblin is that it can run in standalone mode or distributed mode on the cluster. With the extensible framework, it can handle ETL, task partitioning, error handling, state management, data quality checking, data publishing, and job scheduling equally well. This, combined with other features such as auto scalability, fault tolerance, data quality assurance, extensibility make Gobblin a preferred data ingestion tool.
Apache Flume
Apache Flume is a distributed yet reliable service for collecting, aggregating and moving large amounts of log data. The plus point of Flume is that it has a simple and flexible architecture. Flume also uses a simple extensible data model that allows for an online analytic application. It is robust and fault-tolerant with tunable reliability mechanisms and many failovers and recovery mechanisms.
Wavefront
Wavefront is another popular data ingestion tool used widely by companies all over the globe. It is a very powerful tool that makes data analytics very easy. It is a hosted platform for ingesting, storing, visualizing and alerting on metric data. Wavefront can ingest millions of data points per second. Leveraging an intuitive query language, you can manipulate data in real-time and deliver actionable insights. Wavefront is based on a stream processing approach that allows users to manipulate metric data with unparalleled power. There are over 200+ pre-built integrations and dashboards that make it easy to ingest and visualize performance data (metrics, histograms, traces) from every corner of a multi-cloud estate.
Amazon Kinesis
Amazon Kinesis is an Amazon Web Service (AWS) product capable of processing big data in real-time. It’s a fully managed cloud-based service for real-time data processing over large, distributed data streams. Kinesis is capable of processing hundreds of terabytes per hour from large volumes of data from sources like website clickstreams, financial transactions, operating logs, and social media feed. It’s particularly helpful if your company deals with web applications, mobile devices, wearables, industrial sensors, and many software applications and services since these generate staggering amounts of streaming data – sometimes TBs per hour. Kinesis allows this data to be collected, stored, and processed continuously.
[contact_sales title=”Data Analytics To Drive Business Growth” desc=”Get your free copy now” btn_text=”Download Whitepaper” url=”https://accubits.com/white_papers/the-data-journey-unlocking-the-power-of-data-analytics-to-drive-business-growth/”]
Data Ingestion is one of the biggest challenges companies face while building better analytics capabilities. Companies and start-ups need to harness big data to cultivate actionable insights to effectively deliver the best client experience. They need this to predict trends, forecast the market, plan for future needs, and understand their customers. To do this, capturing, or “ingesting”, a large amount of data is the first step, before any predictive modeling, or analytics can happen. For that, companies and start-ups need to invest in the right data ingestion tools and framework.
At Accubits Technologies Inc, we have a large group of highly skilled consultants who are exceptionally qualified in Big data, various data ingestion tools, and their use cases. Our expertise and resources can implement or support all of your big data ingestion requirements and help your organization on its journey towards digital transformation.



